一、数据类型(基础常用)
-
整数:常用十进制数,也可以用十六进制来表示整数。对于比较大的数字,Python是允许在数字中间加上
"_"来进行分割- 整数运算的结果永远是精确的
-
浮点数:对于较大较小的数据,要采用的科学计数法e的n次方
-
字符串:对于Python来说,字符串可以
‘ ’或者“ ”来进行表示都可以。详情- 当有其中一种引号的时候可以用另外一种引号进行区分
sentence = "I'm OK!"- 当包含的内容中同时有两种引号的时候,需要在内容中的引号前打上转义符
sentence = 'I\'m \"OK\"!' #表示的内容是 I'm "OK"!- 转义符可以转义很多字符,例如\n表示换行、\t表示制表符,\\表示\本身,与之相反的是,Python中可以用
r' '表示引号内部的内容不需要转义,避免有些情况确实是需要保留斜杠
-
布尔值:False / True 两种值;可以用and(与运算) 、or(或运算) 、not(非运算)进行布尔运算
-
空值:是Python中的一个特殊值,用
None来表示,与0不同,0是一个值,但是None表示的特殊空值 -
列表、字典 ,etc
二、变量
- 规则:变量名必须是大小写英文、数字和下划线组合,不能以数字开头
- 不用像其他语言一样规定好数据类型,变量可以赋值任意的数据类型,解释器会自动识别,并且同一个变量可以赋值不同的数据类型,这也被称之为动态语言
三、字符串
(一)在Python 3 中,字符串是以Unicode编码的,也就是说Python支持多种语言的,详见
- ord() :函数获取字符的整数表示
- chr() :函数把编码转换为对应的字符
(二)由于Python中的字符串类型是str类型,在内存中以Unicode保存,所以一个字符对应若干个字节(1Byte=8bit),当需要网络传输或者保存到磁盘的时候需要转换为以字节为单位的bytes类型。在Python中,对bytes类型的数据用带b前缀的单引号或者双引号表示:
x = b'abc'
y = b"acd"
####当使用 b'...' 语法创建bytes字面量时,Python期望字符串中只包含 ASCII字符(0-127)- encode(bytes_type) :对
str类型的变量进行编码,可以将字符串编码为指定的bytes(ASCII、Unicode、UTF-8),编码的时候需注意编码的索引范围详见 - decode() :当从网络或者硬盘中读取了数据流,我们则需要将
bytes转换为str- Tips:当str中有部分无法解析的字符,decode方法会报错,若只有一小部分的字符无法识别,可以在方法中传入
errors='ignore'从而忽略错误的字节
- Tips:当str中有部分无法解析的字符,decode方法会报错,若只有一小部分的字符无法识别,可以在方法中传入
x = b'\xe4\xb8\xad\xff'
x.decode('UTF-8',errors='ignore') #输出为"中"- len() :函数计算的是
str的字符数,如果换成bytes类型,len()函数就计算其字节数。(在UTF-8中,一个中文是三字节,一个英文一个字节)
(三)为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*- 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8编码。
(四)格式化:在Python中,采用的格式化方式与C语言相似,用占位符( % )实现
常见的占位符如下表所示:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制数 |
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。(Tips:若需要表示的字符有“%则需要转义%%来表示,与前文的`同理)其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
print('%2d-%02d'%(3,5)) #此时的5的占位符是需要保留两位整数,并且2前面的加了0,代表的是若不足两位则需要补零
print('%.2f' % 3.1415926) #占位符中的数字->指保留几位数- string.format() :适合复杂场景的精细化输出,大致有以下三种方式:
"字符串模板(变量用{var:}括起来,需要与format中的值一一对应)".format(值1, 值2, ...)
# 位置参数,从左到右,从0开始
print("{} {} {}".format("Hello", "World", "!")) # Hello World !
print("{1} {0}".format("World", "Hello")) # Hello World
# 关键字参数
print("{name} is {age} years old".format(name="Alice", age=25))
# 混合使用
print("{0} is {age} years old".format("Alice", age=25))- f-string() :这是最新、最简洁的字符串格式化方法,在字符串前加
f或F。
import math
name = "Alice"
age = 25
#廖雪峰
>>> r = 2.5
>>> s = 3.14 * r ** 2
>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle with radius 2.5 is 19.62
#DS
# 直接插入变量
print(f"{name} is {age} years old") #Alice is 25 years old
# 数字格式化
print(f"Pi: {math.pi:.2f}") # 保留两位小数
print(f"Number: {42:10d}") # 宽度10
print(f"Number: {42:010d}") # 补零
# 字符串格式化
print(f"Name: {name:>10}") # 右对齐 数字十的由来:变量的字符数乘以2
print(f"Name: {name:<10}") # 左对齐
print(f"Name: {name:^10}") # 居中对齐
# 特殊格式化
print(f"Hex: {255:x}") # 十六进制
print(f"Scientific: {1000:e}") # 科学计数法四、列表和元组
(一)列表List
列表可以视为一种特殊的数组,增删改查都是相同的道理,从零开始索引,与C++中数组不同的是列表可以同时存放不同的数据类型,并且操作起来也会更加简单方便;使用 [] 进行定义。
classmate = [‘Bob’,‘Michael’,‘Tracy’] #这就是一个list类型- 增加元素:往list中增加元素有两种办法,一种是默认追加到列表的表尾
append(var),另一种就是使用insert(index,var)将元素增加到指定位置
#append()
classmate.append(Royce) # -->[‘Bob’,‘Michael’,‘Tracy’,‘Royce’]
#insert()
classmate.insert(1,Royce) # -->['Bob','Royce','Michael','Tracy']
- 删除元素 :同样的删除元素也是有两种办法,一种是默认删除末尾
pop(),一种是删除指定位置的元素pop(index)
#末尾
classmates.pop() # -->['Michael', 'Jack', 'Bob', 'Tracy']
#指定位置
classmates.pop(2) # -->['Michael', 'Jack', 'Tracy']- 查找元素 :跟数组的查找方式一样,直接利用下标index来进行索引,正序的最后一个元素的索引为
len(list)-1,特殊的是List可以用负数作为索引号倒序查找,-1为最后一个,-2为倒数第二个,以此类推
classmates[-1] # ->'Tracy'
classmates[-2] # ->'Bob'- 复合 :由于list中的元素可变且类型不限,所以有可能存在元素师list或者tuple的类型
s = ['python', 'java', ['asp', 'php'], 'scheme']
# ||等价于
p = ['asp', 'php']
s = ['python', 'java', p, 'scheme']
要拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
(二)元组Tuple
- 结构与list非常类似,但是tuple一经初始化,就不可以再进行修改,同时其定义是用圆括号
()。
classmates = ('Michael', 'Bob', 'Tracy')
由于不可修改的性质,所以tuple没有插入、增加元素等函数,也不能进行重新赋值,也因此其很大一个作用就是代码就较为安全(有点类似于常量),因此能用tuple代替list 的时候就用tuple。除此之外,索引还是跟list是一样的方法。
- tuple的定义会有一个陷阱:在定义tuple的时候,其元素就需要确定下来,如果是想定义空的元组,则可以:
t = () # 为空但是如果要定义只有一个元素的元组,则会发生歧义,这是因为()既可以表示元组,又可以表示数学中的小括号,这样会产生歧义,所以当需要表明的是元素的个数的时候需要在数字后面加上,进行区分(如下所示):
t = (1) # ->这样定义出来的是一个整数,t = 1;
t = (1,) # ->这样定义出来的就是一个有 1 这个元素的的元组- “可变的”元组
定义上是规定的元组元素是不可以改变的,但是会存在特殊情况:因为元组的元素也是可以是任意类型的变量,那如果元组的元素是一个可变的列表呢,这个时候list内容是可以修改,表面上是实现了tuple元素的修改,但从指针的指向维度来看待的话就会比较好理解。
t = ('a', 'b', ['A', 'B'])
t[2][0] = 'X'
t[2][1] = 'Y'
print(t) # ->('a', 'b', ['X', 'Y'])修改前:
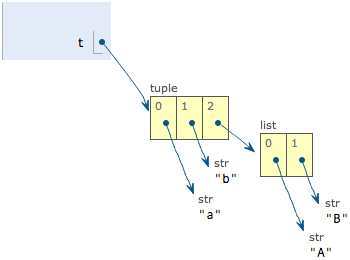
修改后:
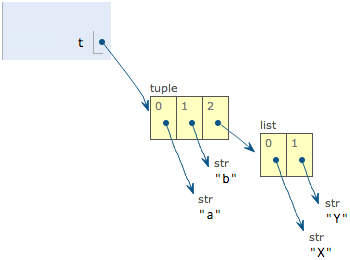
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
五、条件判断
基本逻辑与C++是一样的,不一样的是,Python的条件是不需要圆括号和中括号的,语法比较简洁干练
if <条件判断1>:
<执行1>
elif <条件判断2>: #elif就是else if的简称
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>六、输入输出
(一)输出 Print()
print('The quick brown fox', 'jumps over', 'the lazy dog') # print()函数也可以接受多个字符串,用逗号,隔开,就可以连成一串输出
print(100 + 200) # 也可以打印整数,或者计算结果==值得注意的是==:Python的print()默认有一个 end='\n' 参数,当想要输出在同一行的时候可以显式输出,让end参数为空即可
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name, end=' ') # 使用空格代替换行符
# 输出: Michael Bob Tracy (二)输入 Input()
- 值得注意的是:
input()返回的数据类型是str,所以在很多程序当中需要注意变量类型的转换
s = input('birth: ')
birth = int(s)
if birth < 2000: #此前若是不进行类型转换直接比较会出现报错
print('00前')
else:
print('00后')七、模式匹配
- 简单匹配
针对某个变量匹配多种情况的时候,若是用if else语句,当分类情况较多的时候,代码的可读性会比较差,可以用match语句。
score = 'B'
if score == 'A':
print('score is A.')
elif score == 'B':
print('score is B.')
elif score == 'C':
print('score is C.')
else:
print('invalid score.')
# 改写成match语句
match score:
case 'A':
print('score is A.')
case 'B':
print('score is B.')
case 'C':
print('score is C.')
case _: # _表示匹配到其他任何情况
print('score is ???.')- 复杂匹配
match语句是十分灵活的,除了可以匹配简单的单个值外,还可以匹配多个值、除此之外,还可以匹配一定范围,并且把匹配后的值绑定到变量:
age = 15
match age:
case x if x < 10:
print(f'< 10 years old: {x}')
case 10:
print('10 years old.')
case 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18:
print('11~18 years old.')
case 19:
print('19 years old.')
case _:
print('not sure.')- 匹配列表 【难点】
args = ['gcc', 'hello.c', 'world.c']
# args = ['clean']
# args = ['gcc']
match args:
# 如果仅出现gcc,报错:
case ['gcc']:
print('gcc: missing source file(s).')
# 出现gcc,且至少指定了一个文件:
case ['gcc', file1, *files]:
print('gcc compile: ' + file1 + ', ' + ', '.join(files))
# 仅出现clean:
case ['clean']:
print('clean')
case _:
print('invalid command.')第一个case ['gcc']表示列表仅有'gcc'一个字符串,没有指定文件名,报错;
第二个case ['gcc', file1, *files]表示列表第一个字符串是'gcc',第二个字符串绑定到变量file1,后面的任意个字符串绑定到*files(符号*的作用将在Python_函数的参数中讲解),它实际上表示至少指定一个文件;
第三个case ['clean']表示列表仅有'clean'一个字符串;
最后一个case _表示其他所有情况。
可见,match语句的匹配规则非常灵活,可以写出非常简洁的代码。
八、循环
Python中有两种循环,for .. in ..循环和 while循环
for .. in ..循环:for x in ...循环就是把每个元素代入变量x,然后执行缩进块的语句。执行的次数是由要遍历的变量的长度决定
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
#Michael
#Bob
#Tracywhile循环 :满足条件时候就一直循环,直到不符合循环条件停止
#计算100以内的奇数之和
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)- break & continue
break是用来退出循环;continue是用来结束此次循环,从continue后的循环语句不再执行,直接跳转到下一次循环的。
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
#执行上面的代码可以看到,打印的不再是1~10,而是1,3,5,7,9。九、字典与集合
(一)Dictionary 字典
字典,dictionary,在其他语言中也叫map。是一种key-value的查询模式,
#例
names = ['Michael', 'Bob', 'Tracy']
scores = [95, 75, 85]
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长(类似数组的从头遍历)。如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩存放的内存空间,所以无论这个表有多大,查找速度都不会变慢。
1.赋值
与正常的变量赋值一样,除了初始化赋值,也可以通过key进行重赋值,值以最新赋值为准
d['Jack'] = 90
print(d['Jack']) # 90
d['Jack'] =88
print(d['Jack']) # 882.操作函数
- in() 判断key是否在dict中
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
print('Tomas' in d)
# False- get()
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d.get('Thomas') #在Python的交互端中,Python的none不会显示出来
q = d.get('Thomas', -1) # -1
- pop(key) 删除key和对应的value
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d.pop('Bob') #{'Michael': 95, 'Tracy': 85}Compare to List :
dict有以下特点:
a、查找和插入的速度极快,不会随着key的增加而变慢
b、需要占用大量的内存,内存浪费多
list则恰恰相反:
a、查找和插入的时间随着元素的增加而增加;
b、占用空间小,浪费内存很少
==底层算法是哈希算法,因此对key的要求是不可变值==。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key。Dictionary与List的区别就在与不会随着key的增多,而降慢查询速度,适用于有查询速度要求的场景;但是由于key的值也需要占用空间,属于是空间换时间了。
(二)Set 集合
dict与set类似,set集合是一种有无序性、唯一性的一组key的结合,但是它不储存value值。
s = {1, 2, 3} \ s = set([1, 2, 3]) #两种定义方法重复元素会被set自动过滤掉
s = {1, 1, 2, 2, 3, 3}
print(s) #{1, 2, 3}add(key)方法:可以添加元素到set中。(可以重复添加,但不会有效果):
s.add(4) #{1,2,3,4}
s.add(4) #{1,2,3,4}-
remove(key)方法:可以删除元素 -
由于set的无序性和唯一性,有个很大的作用就是用求并集和交集,需要注意的是set跟dict类似的,是需要不可变元素。dict的key是需要不可变元素,值是可以任意类型。
编码(Extra)
编码是在处理字符串的时候的很重要的一个解读机制:因为正常的计算机只能读懂数字,也就是机器语言,当需要处理文本的时候就需要将文本转变为数字,这个时候就需要用到一个统一的机制,编码。编码总的来说可以分为以下三种类型:
- ASCII :美国人先创的,所以表示的都是英文字符和阿拉伯数字
- Unicode :ASCII的扩充,可以表示更多字符和各国语言;使用场景:在内存当中统一使用的都是此类型
- UTF-8 :为了解决Unicode扩充表示范围带来的内存浪费问题,应运而生;使用场景:当需要保存到硬盘或者数据传输的时候,会将Unicode编码转换为UTF-8